Final Blogpost: Drift Management Strategies Benchmark
Evaluating approaches in tackling drifts
Background
Hello there! I’m William and this is my final blog for my proposal “Developing A Comprehensive Pipeline to Benchmark Drift Management Approaches” under the mentorship of Ray Andrew Sinurat and Sandeep Madireddy under the LAST project.
If you’re not familiar with it, this project aims to address the issue of model aging, where machine learning (ML) models experience a decline in effectiveness over time due to environmental changes, known as drift. My goal is to design an extensible pipeline that evaluates and benchmarks the robustness of state-of-the-art algorithms in addressing these drifts.
Deliverables
You can find my list of deliverables here:
- Final report, this blog is a summarized version of my final report, so do take a look if you’d like to know more!
- Github repository, contains code as well as the raw experiment results.
- Trovi artifact
Evaluation
Here are some of the graphs that show the performance of every algorithm on the created datasets. For more graphs and figures, you can check out my final report:
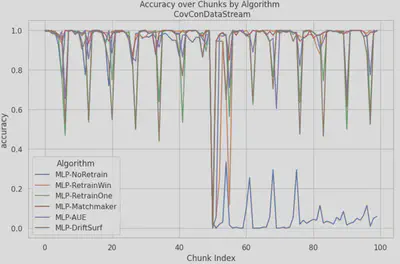
- CIRCLE: AUE demonstrates stability, maintaining a high accuracy even as the data drifts, which may be due to its ensemble nature. It is even more stable than baseline retraining algorithms. Matchmaker is also able to recover quickly upon experiencing drift, which maybe again due to its ranking the most high performing models to do inference, recovering faster than RetrainWin. On the other hand, DriftSurf experiences several random drops in accuracy, indicating that it can be somewhat unstable.
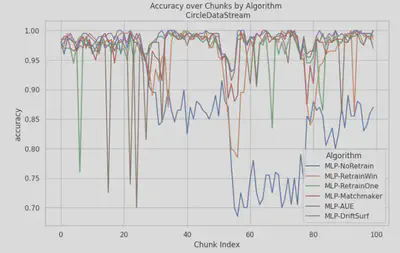
- SINE: Similar to CIRCLE, AUE demonstrates stability throughout the dataset, maintaining a high accuracy even as the data drifts. Matchmaker however was struggling to adapt as fast when encountering such a sudden drift, as it needed some time/windows to recover from the drop. Driftsurf’s performance was notably better than baseline, as unlike them, it was able to recover successfully fairly quickly upon experiencing drift.
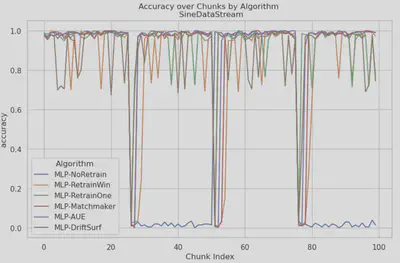
- CovCon: In CovCon, Matchmaker was able to achieve the best accuracy, as it is able to select the models most relevant to each incoming batch (model trained on the most similar features), performing comparably to retrain window. Most of the other algorithms suffered in this dataset, particularly AUE whose performance is now becoming comparable to the rest of the algorithms and baseline.
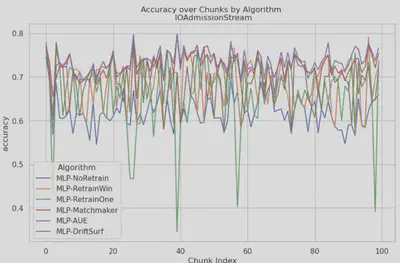
- IOAdmission: Performance on this dataset was led by AUE, which was able to maintain impressive stability amongst all of the algorithms used. This is followed closely by Matchmaker. The other algorithms used undergo a lot of fluctuations in accuracy.
Findings / Discussion
From the experiments conducted, the findings are as follows:
Matchmaker was able to perform particularly well in the CovCon dataset. This maybe due to its ability to choose the most relevant trained model from its ensemble during inference time. Its training time is also the best compared to other algorithms, especially considering that it keeps data for training an additional random forest model for ranking the models. However, its inference time was the longest amongst all other algorithms. This may be due to the fact that on inference time, one needs to traverse all of the leaf nodes of the random forest used to rank it (computing covariate shift).
AUE was able to perform particularly well in the CIRCLE and IOAdmission dataset. However, it is quite competitive on other datasets too. It’s weighting function which incentives highly relevant models and eviction of less relevant ones may be key. Its inference time is decent compared to other algorithms, being slower than most baselines and Driftsurf, but faster than Matchmaker. However, its training time took the longest amongst other competitors, as it has an expensive weighting function to weight, evict, or retrain models on every retraining.
DriftSurf was performing very similarly to the RetrainWindow baseline, in almost all datasets, except for IO Admission and SINE where it did better. This may be because of the fact that it maintains only at most 2 models every iteration, and as such, its performance was not competitive against the mult-models approach used in Matchmaker and AUE. On the plus side, its inference time is comparable to the baseline single model, having almost no inference overhead compared to most of the competitors out there. Another plausible explanation for the lack of performance is the lack of tuning, such as the number of windows retained, the length of its reactive period, and its reactivity sensitivity threshold. A better performance could be achieved if these parameters were tuned further.
Next Steps
These are some of the potential extensions for this project:
- Optimize Matchmaker’s inference time improving Matchmaker’s efficiency, especially in covariate shift ranking, can reduce inference time. Simplifying the random forest traversal could make Matchmaker faster without impacting performance.
- Extending the work to include other frameworks like TensorFlow or PyTorch, as it can now only support a scikit-learn base model.
Thank you for reading!
William Nixon
Student at Bandung Institute of Technology (ITB), Bandung
William is a Computer Science B.S. Student at Bandung Institute of Technology (ITB).